随着 AI 中 GPU 含量的加大,25 年美国早已寡头的云服务行业,开始冒出一堆新兴云公司。本篇,海豚君以新云之一$Coreweave(CRWV.US) 来作为研究对象,来尝试理解一下 AI 时代,基础云服务的生意模式、要素变化,以及 CoreWeave 是不是一个有长期价值,从事好生意的好公司。
而在下篇中展开定量角度,对公司的收入空间、成本结构、资金的投入产出等问题来判断目前节点,公司的投资性价比如何。
以下为详细分析:
一、看待云计算商业模式的一种视角
首先,CoreWeave 所属 IaaS 行业的商业模式——主要价值体现在整合上游供给,匹配下游需求,用大规模的需求来分摊机房建设和研发成本上。
1.1、需求的整合
这部分简单来说,就是共享机房。原本每个企业都需要 IT 搞一个机房,但单独建机房不仅成本高,而且利用率不高,比如电商用云高峰是在双十一,游戏云用量暑假;视频用云是在下班后,而钉钉用云是在上班时。
一个公共机房,可以把使用云服务的谷峰和谷底都平滑掉,从而提高机房的产能利用率。并且,对云服务而言,客户数量越多,同时他们的需求曲线越多样化(例如属于不同行业、处在不同时区等)就越好。 (微软 CEO Nadella 在近期的电话会中,明确表述过类似的观点)
1.2、供给的整合
一个完整、可投入运营的 IaaS 云计算中心,是建立在三个层级的软硬件基础设施上,包括第一层的土建和能源供应,第二层的各类 IT 和非 IT 类硬件设备,以及第三层的各类软件和工程能力。第三层以研发人员投入为主,不太涉及 Capex 投入,接下来重点谈论 “看得见摸得着” 的前两层:
1)第一层 -- 土建 & 能源:简单来说,找到土地,建设厂房,创造一个能放服务器的地方。取决于其面积/规模大小,建设一个全新数据中心(空建筑)所需的时间大约在 1~3 年不等。
云服务商可自建这些不动产,也可以给外包来建设和管理,如 Equinix,Digital Realty 等直接租赁现成库房。
除了土地和库房建筑外,数据中心还需有电力、水源和网络链接等外部能源的稳定供应,也是目前云服务扩张产能的主要卡点之一。不过能源供应主要是运营开始后产生的持续成本,并不需要太多前置投入。
根据调研,第一层级的土地和库房建设,大约会占到数据中心建设总投入(不包含软件)的约 5%~10%。
2) 第二层--IT 类设备:在土地&库房的基础上,支撑起一个数据中心的第二层是各类的硬件设备,首先是与提供算力直接相关的各类 IT 设备,包括:
a. 服务器:数据中心中最重要的部分,基本可以理解为更大块头的电脑,同样由高性能芯片(GPU/CPU),主板,内存等主要组件构成。目前高性能芯片和内存也是云计算中心供应链上的另一主要卡点。
在这个核心组件上,云服务商们同样可以 “自行设计 +ODM 代工”,或者直接向 Dell 等供应商采买。目前来看Azure,AWS 等头部服务商会更常使用自行设计的服务器,而CoreWeave 则是以直接向上游供应商采买/租赁装配完成的整机为主。
b. 网络设备:在传统云计算中心内,主要包括各种交换机设备 -- 实现服务器之间的数据传输;路由设备 -- 负责将数据中心与外部网络的链接;以及各类链接组件,如光模块、光纤线缆或铜缆。
在 AI 时代,由于各服务器之间传输数据速度要求的大幅提升,需要更高性能的 AI 专用交换设备,如英伟达 Quantum 等。
c. 存储设备:为了存储运营过程中产生的大量数据,云计算中心中也需配置大量机械或固态硬盘构成的集群。
根据调研和行业惯例,IT 类设备占数据中心硬件投入的绝对大头,占比可达 60%~70%。其中服务器是最核心的部分,能达到总投入的约 40%~50%。
且在 AI 时代,由于算力芯片、内存、高性能交换设备的单价普遍更高,AI 计算中心的 IT 类设备占总投入的比重会更高些。
3)第二层—非 IT 类设备:除了上述和云计算直接相关的 IT 类设备外,计算中心也需要配置大量的非 IT 类设备以维持运营,主要包括:
a. 供电设备:包括变压设备将外部高压电力转化为内用;备用发电机组,在外部停电时,能继续维持供电较长时间;UPS 不间断电源,,在意味情况下在短时间维持平稳供电,保持服务器等设备正常运营且不被损坏;储能系统,帮助平衡耗电的波峰波谷,或外部断电的情况。
b. 冷却设备:为服务器集群或者整个数据中心进行散热的系统,大体可分为风冷和液冷散热。随着 AI 时代单卡算力/发热的大幅提升,对液冷散热的采用率越来越多。
c. 机柜:即用以承载其他设备的各类物理框架,虽然这些 “铁架” 并没有任何技术含量,但如何进行布局并和其他系统整合,以实现更高效的帮助散热、数据传输等仍是存在一定行业 “know-how”。
d. 监控 & 备灾: 实时检测各设备运转情况,还有电力供应,散热,网络状况的各类设备,帮助监控并解决死机、断电、断网、火灾等各类异常情况。
根据一些调研, 能源和冷却等非 IT 设备则占据总投入剩下的约 20%~30%。在 AI 数据中心中的比重则更少些。

二、长期确定性不高
由上文可见,IaaS 云服务的商业模式的核心价值来源于对算力的需求和算力生产要素的整合,以在更大的规模下实现更高效的匹配和更低的运营成本。
那么自然的,对一个云服务商,其向下整合需求,以及向上整合供应链的能力(解决产业链卡点,对供应商的掌控和议价能力)是其核心竞争力之一。而在上述 “硬实力” 之外,云服务商的 “软实力”(如软件和工程能力)也是构成差异化竞争优势的重要因素之一,此在后文会单独讨论。
2.1、高度依赖少数巨头的客户结构
首先从整合需求能力的角度,“旧时代” 传统云巨头的客户结构高度分散,由数量众多的不同类型企业汇聚而成,任何单一客户占总收入的比重都不高。
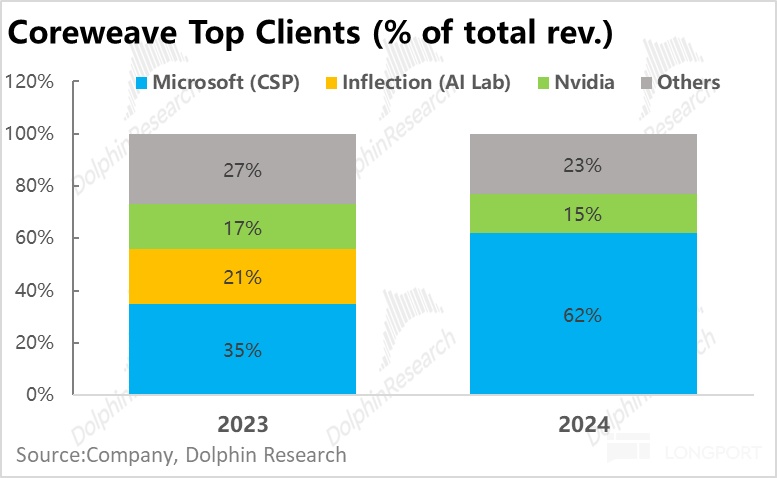
CoreWeave客户结构高度集中,目前基本只由 AI 模型独角兽,和有能力独自研发/优化 AI 模型的大型科技公司构成。
在2024 财年 CoreWeave 约$19 亿的总营收中,接近 80% 的收入只来自两家客户公司 -- 微软和英伟达,其中微软一家就占了当年总收入的 62%。
更 “实时反映现状” 的在手合约月同样呈现用户集中的现状:在 3Q25 披露的$556 亿未履约合同余额中,来自 OpenAI,微软和 Meta 这三家的合约金额就接近$470 亿。
由于与微软和合约大部分也是为了满足 OpenAI 的需求,因此可能存在重复计算的部分,但也表明公司的最终需求实际更加集中于 OpenAI 这一家公司。
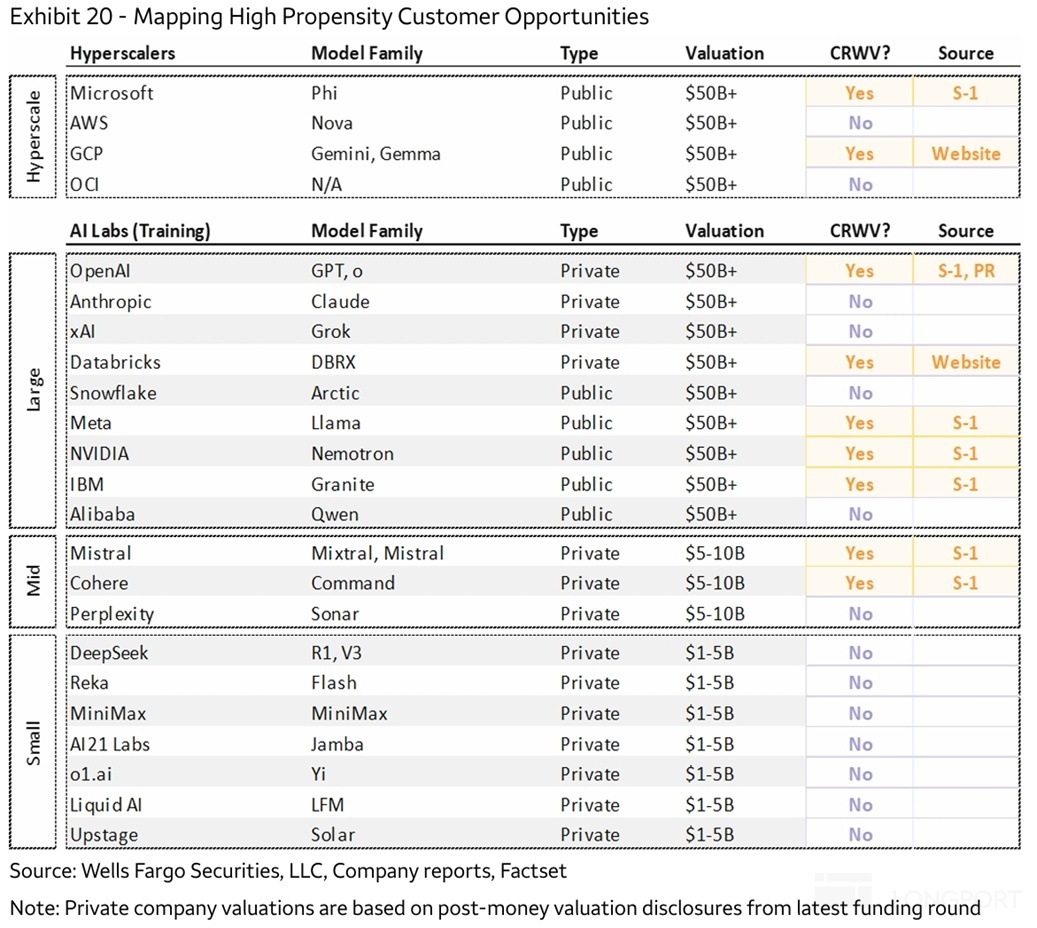
此外,CoreWeave 与 Google(最终需求也是 OpenAI),以和 Databrick,IBM,Cohere,Poolside 等科技公司据报道也有合作。
但整体上,CoreWeave 的大部分业务高度依赖于少数几家头部公司(OpenAI 为主),剩下 “聚少成多” 的其他客户也主要是 AI/科技这一单一类型公司。
因此从商业模式上,不同于传统云通过大量行业不同、类型分散的客户结构,能充分平滑需求波动,降低某些行业下行导致的风险。高度集中于少数企业和有限行业的 CoreWeave 等 AI 新云,无疑面临着更大的需求风险(例如丢失大客户),且面对少数贡献公司大部分收入的头部客户,逻辑上也很难有议价能力。

2.2、说完 “硬实力”,公司 “软实力” 又如何?
云服务商另一个容易形成差异化竞争力之处,在于软件和工程能力这类 “软实力” 上。根据调研,CoreWeave 在 “软实力” 上的主要优势是能在短时间内(如 3~5 个月内)将一个云计算中心从零到上线的工程规划能力,但在软件/编程等能力上能力相对欠缺。
1)CoreWeave 的技术服务
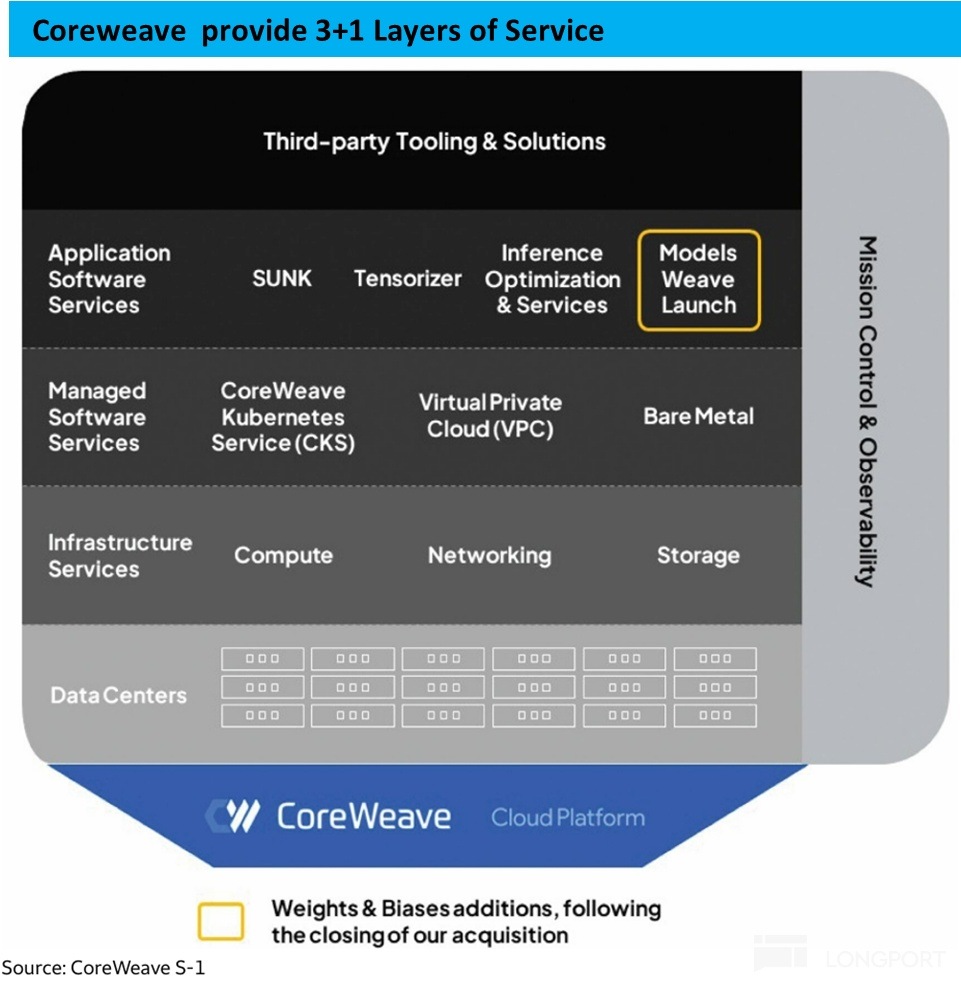
简要介绍下 CoreWeave 提供的服务类型,根据公司在招股书中的披露,可以分为 3+1 大类:
a. Infrastructure Service: 最简单、直接地向客户出租其所需的高性能芯片,存储硬盘等单纯的硬件设施,不附带任何软件服务。结合报道,这类纯粹出租硬件的业务占比很小(没有官方的披露,仅做大概的定性参考)
b. Managed Software Service: 在硬件之上,包含一些基础的软件管理、调用工具的服务。重点说下Bare Metal 模式——传统云服务是出租虚拟机,但 Bare Metal 的用户 100% 独享其租用的物理服务器,自行决定如何使用/分配这些资源。根据报道,Bare Metal 是目前公司头部大客户普遍(至少微软是)采取的服务模式。
这一点也是 AI 云和传统云的主要区别之一:传统云下,业务对算力的需求普遍是波动的,因此服务商能将同一批物理算力动态的分配给不同的用户,以提高算力的利用率并获取更多的收入和利润。
而在 AI 时代,特别是 AI 训练对算力的需求则普遍是大规模且持续性地集中使用。比如每次训练新 AI 模型,可能就需要万张 GPU 以上的大规模集群,在几个星期甚至几个月内近乎 100% 的持续使用。AI 推理对算力的要求不像训练这么集中,但大概率也比传统情况下更集中些。
因此,这种使用算力的模式,决定了 AI(尤其是训练)对算力的需求是更独占、排他性的。在这种情况下,云服务商并没有多少操作空间能够把物理算力动态分配给不同客户。
BareMetal 外,这一层级下还有 CKS 和 VPC 这种类虚拟机服务,和传统云业务的租赁模式大体相近。
c. Application Software Service:这一层级的服务这可粗略类比为 PaaS 类型的服务。除了单纯提供虚拟机或其他简单软件服务外,这一层内公司会提供更加高级、丰富的软件功能。例如,客户帮助客户优化资源或者任务的分配,提供已预加载好的一些 AI 模型或其他功能供客户直接使用。
d. Mission Control & Observability:帮用户监控硬件的使用情况,任务的执行进展,并提供渠道供客户查看。并在运行周期内,保证硬件和任务的正常运营,即时解决报错、停机等问题。
2)CoreWeave 的软件能力如何?
根据市场内的一些说法, CoreWeave 在编程/软件方面不具备优势,而是强在如何更快速、有效的布置和落地数据中心的工程能力。
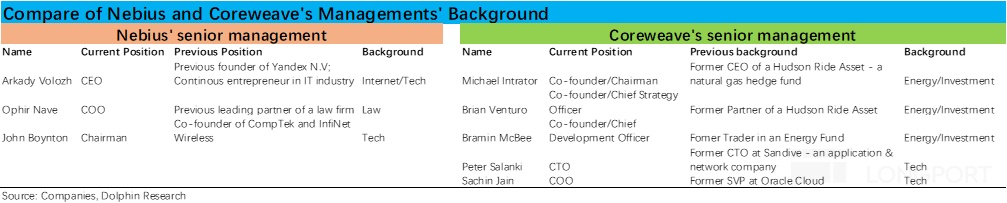
相比之下,据悉公司在新云领域内主要的竞争对手之一—Nebius 则在软件/编程能力上更有优势。作为一个侧面的证据,从两家公司的创始人和核心管理层的不同背景,也能对两家公司不同的导向窥见一二。
由下表可以看到,Nebius 的 CEO 是俄罗斯最大的互联网科技公司 Yandex 的创始人。其董事长则是 CompTex(俄罗斯电信和网络设备龙头)和 InfiNet(俄罗斯无线宽带技术龙头)两家公司的共同创始人之一。
而CoreWeave 的三位核心联合创始人都是来自于能源投资领域,且公司创立之初是从事 Bitcoin 矿场挖矿业务,可以说基本没有科技或云计算相关的经验和背景。
高级管理人之中,只有 CTO 和 COO 这两个外部的职业经理人有用科技行业背景,其中 COO 原本是 Oracle Cloud 部门的高级副总裁。
从核心管理层的背景来看,CoreWeave 在技术能力上确实不像有多少积累,反而在如何获取能源供给这个供给卡点上有一定优势。
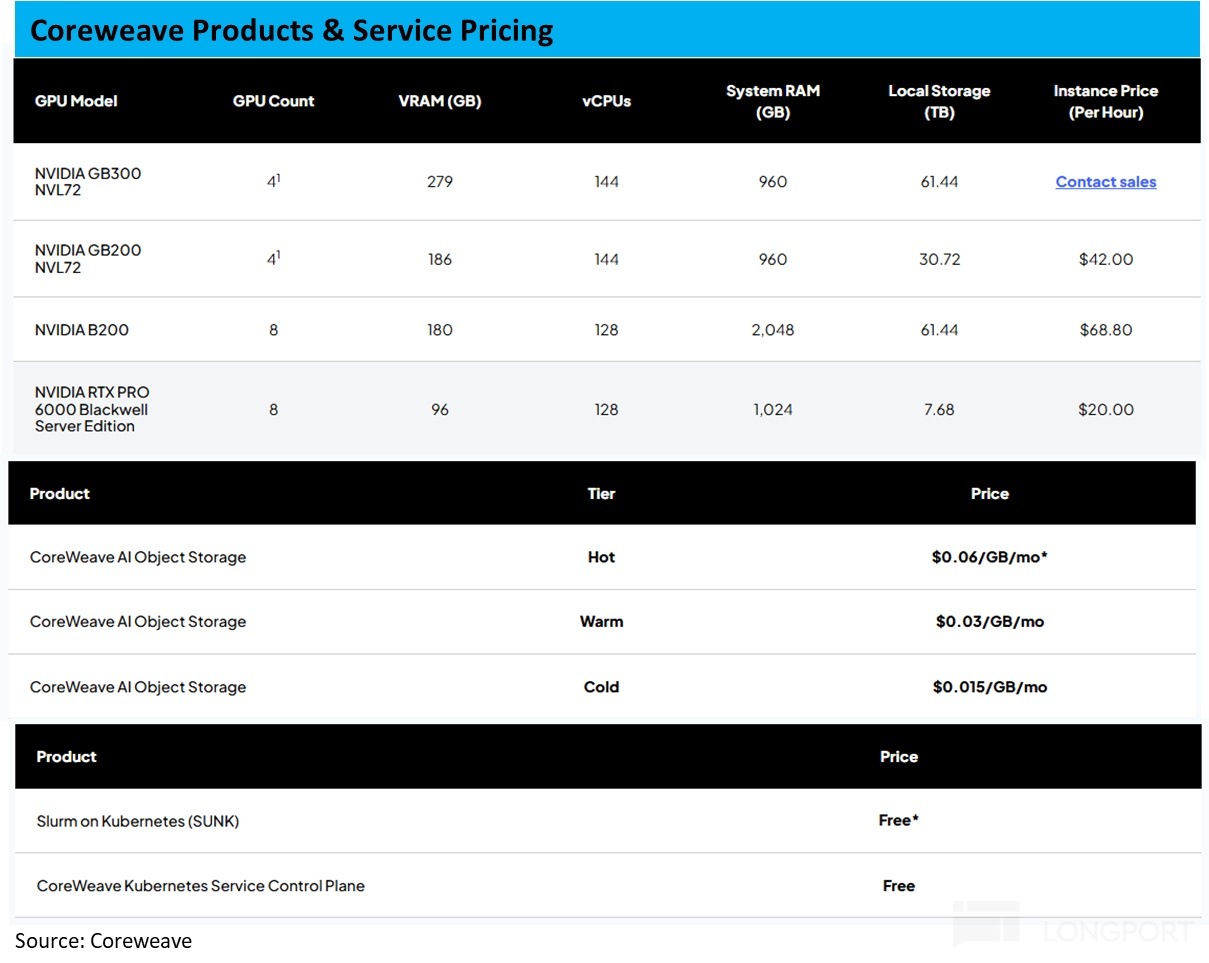
且从现状上,公司的收费标准也仍基本是基于租用的硬件来定价的,对如前文提及的 Slum 和监控服务等都是最为免费的附加功能提供的。
3)“软实力” 高低的影响是什么?
那么,像 CoreWeave 这类工程能力强但软件技术相对较弱的情况,对公司的中期和长期发展可能造成什么影响?
首先从优势上看,当前 CoreWeave 得以高速发展时代性因素,就是 AI 时代算力的严重供不应求和很快的迭代速度。
而CoreWeave 优异高效的工程能力,能够在 3 个月左右完成对数据中心的装配到上线运营(当然前提是相关设备和能源供应等都已到位),是所有云服务商中最快速的(之一),能很好的适配目前头部科技公司或 AI 独角兽对算力需求的快速迭代。
另一个角度,由于 CoreWeave 的主要客户是微软、OpenAI、Meta、Google 等头部科技公司。这些巨头自身的技术实力很强,也普遍是采用 Bare Metal 类型的服务,以便自己对底层硬件有更好的把控,也确实不太需要 CoreWeave 提供多少软件层的服务。
但从中长期角度, CoreWeave 要继续在行业内保持独特竞争力,或者说要优化客户和收入结构,减少对大客户的依赖,那么就必须增加大量传统或中小型企业客户,而这些客户的技术实力显然不会很强,此时作为服务商的CoreWeave 就必须要能够提供比较优异技术/软件服务。
因此关键是,在当前算力供不应求且依赖于少数大客户的红利窗口期结束前,公司在先做大业务规模后,能否在相对短板的技术能力上也完成补强。
2.3、CoreWeave 在供给端的议价能力如何?
从上文来看,部分出于 AI 时代的时代性特征,部分是由于 CoreWeave 自身在客户结构和技术能力上的 “缺陷”,CoreWeave 在需求整合能力上,属于走量型,质量一般。那么供应链整合能力上,CoreWeave 的 “实力” 又如何?
同样根据公司的披露,其主要供应商也相当的集中。在 23 和 24 年,仅 3 家最大的供应商就占据了公司总采购额的 8~9 成。结合数据中心投入在不同板块的大致投入占比,和相关新闻报道,大致可以做出以下推测:
a. 最大供应商 -- 英伟达:据推测,23~24 年占据公司总采购额约 5~6 成的最大供应商应当就是英伟达—提供最大单一硬件 GPU 和高性能连接系统/硬件等(英伟达 Spectrum-X 和 Quantum-X)。
b. 第二或第三大供应商--Dell 和 Super Micro:结合公司的披露和相关报道,可以推测另两大占总采购额约 1~2 成的供应商,很有可能是两家服务器供应商 Dell 和 Super Micro。
c. 其他重要供应商:除了以上三家之外,根据相关披露,CoreWeave 在土地、建筑、电力供应等基础设施上,也有两家有公开披露的供应商—Core Scientific 和 Applied Digital。
其中Core Scientific 是一家从事比特币矿机和数据中心托管的公司(和 CoreWeave 早年间类似),CoreWeave 原本是向其租赁土建等基础设施,但在 2025 年以 90 亿美元的对价将其全资收购。标志着 CoreWeave 从轻资产的纯租赁,部分转向了自行经营。
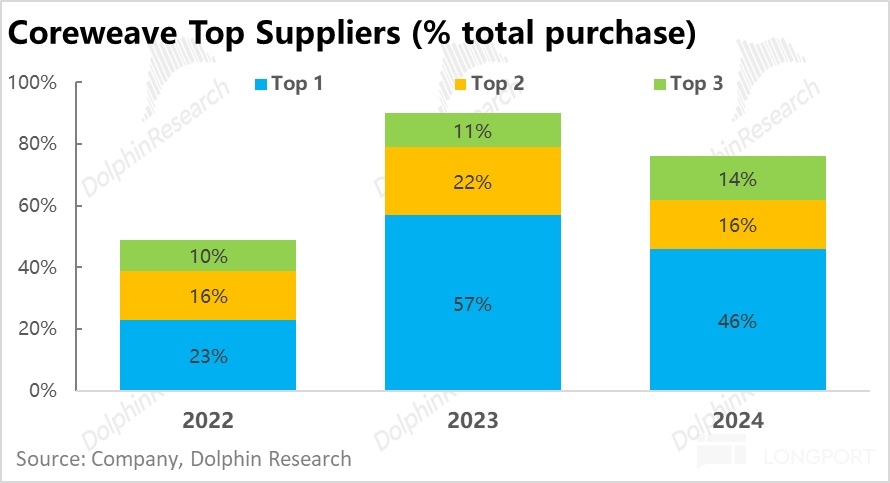
那么从逻辑上看,CoreWeave 在向上游供应链的议价能力上又是否出色?简单来说,并不好。首先从三家运营商就占公司总采购额的 8~9 成,这一点就意味着一旦某家大供应商停止供货就足以对公司的供应链产生巨大冲击。
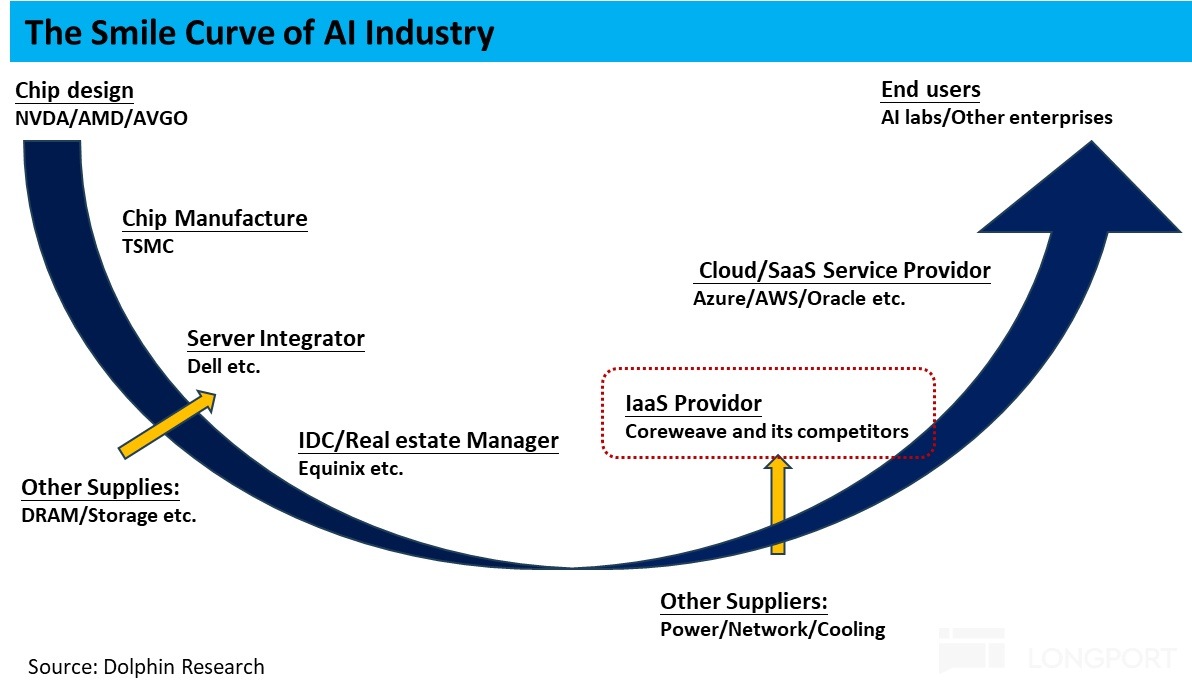
下图概括性的展示了整个云服务从上游到下游的产业链,如著名的 “微笑曲线”,海豚君认为在算力产业链中的两端 -- 更靠上游设计和更靠下游接触终端用户的部分是产业链中议价能力相对更强的。
而 CoreWeave 目前处于产业链中相对中间的 “低价值” 位置,向上需要依赖多层级的供应商,向下目前也主要是作为三大头部云厂商的供应商,而不太直接接触分散的终端客户。
更具体来看,面对其最大的供应商英伟达,既无自研芯片的科技实力,也没有巨头那般资金实力的 CoreWeave 显然没有多少议价能力(虽然 CoreWeave 是英伟达的 “亲儿子”,但这是单方面的扶持,而非 CoreWeave 的能力)。
而对于第二、第三大供应商--Dell 等服务器供应商,虽然CoreWeave 和 Dell 两者之间都有不小的依赖,毕竟 CoreWeave 也是是 Dell 在 AI 服务器的重要客户之一。但仍体现 CoreWeave 相对劣势的关键点是,CoreWeave 是向 Dell 直接采购包括机架、冷却系统、整机服务器设备,以及一些基础软件功能的整体解决方案。
这一定程度上侧面表明,CoreWeave 并不像三大云巨头,乃至国内阿里之类拥有自行设计整套服务器设备的能力。而简单的逻辑是,对供应商依赖越多,就需要向其让渡更多利润。
那么从结果来看,市场共识认为 CoreWeave 的真实毛利率只在 25%~30% 左右,较微软智慧云板块 60% 以上的毛利率明显偏低。也正是 CoreWeave 在产业链中议价能力不强的体现。
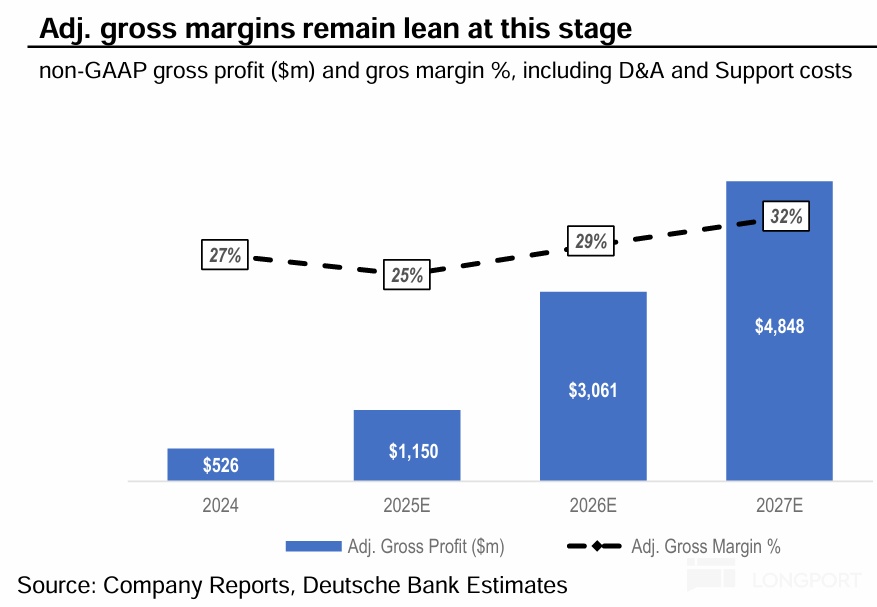
2.4、观点小结 -- 占产业链的价值量有限:
小结以上分析,从云服务作为算力需求和供给最终整合方的商业模式角度,CoreWeave 看起来并不像一个在 3~5 年后仍能有较强的确定性在巨头林立的云服务市场保持独特的竞争力和一定市场地位的公司。并不太能看到在供需稳定后,CoreWeave 有和三大云巨头正面竞争的实力。
其主要问题包括:
a. 客户结构目前高度集中于少数大公司和少数行业,一旦丢失某大客户会有严重影响(其最大客户之一微软就明确表示过长期来看更愿意自建数据中心,而非像 CoreWeave 等外部供应商租赁);
b. 目前提供的服务主要是 “偏基础” 的硬件租赁,附加值有限。即不利于绑定现有客户不丢失,也不利于后续向更下游的中小客户或者向更赚钱的 PaaS 层业务拓展。
c. 同样过度依赖少数几个大供应商,定制化能力仍比较弱,当前体量也不足以成为对头部供应商举足轻重的大客户。因此在产业链内占据的价值量有限。
当然中长期的确定性不高,并不能证伪公司中期内有很高的成长性和不低的确定性,在下篇中海豚君会从中短期的视角内,看待是什么原因帮助公司能在新云中脱颖而出。
<正文结束>
本文的风险披露与声明:海豚研究免责声明及一般披露
内容来源:长桥海豚投研
1998-2026深圳市财华智库信息技术有限公司 版权所有
经营许可证编号:粤B2-20190408
粤ICP备12006556号
 财华财经APP下载
财华财经APP下载

